Serverless Analytics Pipelines with Terraform
From SNS to OpenSearch in Minutes
When you’re building automation systems that generate thousands of events per hour, you need analytics infrastructure that’s both robust and simple to deploy.
We learned this the hard way during a recent account migration. Our production analytics pipeline - processing thousands of booking automation events daily - had to be rebuilt from scratch in a new AWS account. Rather than recreate the same bespoke infrastructure, we took a step back and abstracted the patterns into reusable Terraform modules.
The result? Two focused modules that make event analytics almost trivial to deploy and maintain.

The Problem: Event Data Everywhere, Insights Nowhere
Modern automation systems generate events constantly:
- Booking jobs starting and completing
- API requests and responses
- User flows and session data
- System health metrics
From Self-Managed to Serverless
We started with the traditional approach - Logstash clusters processing events from message queues:
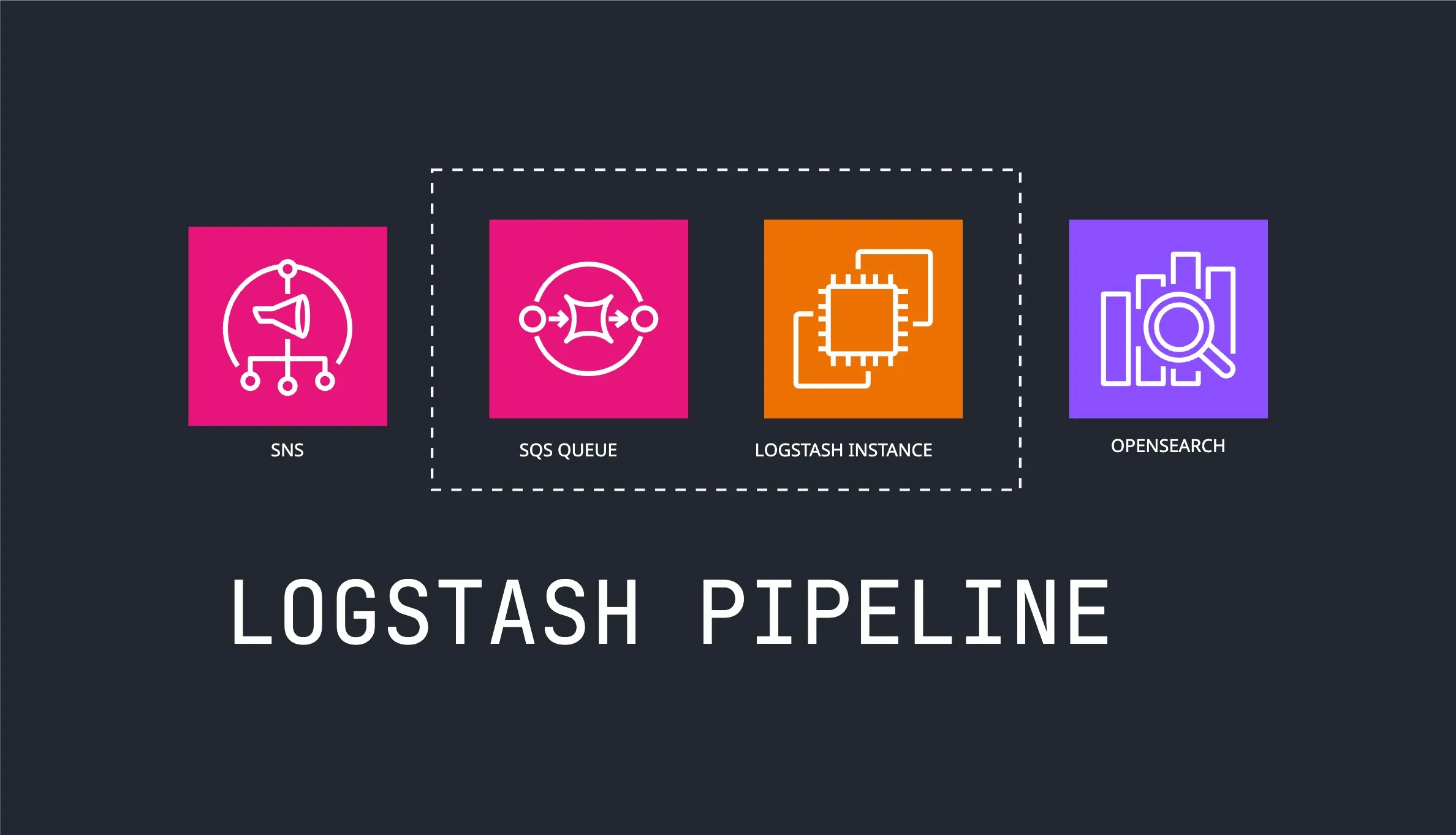
This worked, but came with operational overhead:
- Managing Logstash instances and scaling
- Complex configuration files
- Monitoring multiple moving parts
- Infrastructure costs even during low traffic
Then we discovered Kinesis Firehose could act as “managed Logstash” - handling the same data transformation and delivery patterns, but serverless:
The structural similarity is striking. Compare Logstash configuration:
# Logstash pipeline
input {
sqs {
queue => "analytics-events"
}
}
filter {
json {
source => "message"
}
mutate {
rename => { "created_at" => "@timestamp" }
}
}
output {
opensearch {
hosts => ["https://search-domain.es.amazonaws.com"]
}
s3 {
bucket => "analytics-data"
}
}With our serverless pipeline:
# Terraform serverless pipeline
module "booking_analytics" {
source = "git::https://github.com/ql4b/terraform-aws-analytics-pipeline.git"
context = module.label.context
attributes = ["booking"]
create_queue = true
data_sources = [{ # input
type = "sns"
arn = aws_sns_topic.booking_events.arn
}]
enable_transform = true
transform_template = "sns-transform.js"
transform = { # filter
mappings = {
"@timestamp" = "created_at"
}
}
enable_opensearch = true # output
opensearch_config = {
domain_arn = module.opensearch.domain_arn
index_name = "booking-events"
index_rotation_period = "OneMonth"
buffering_size = 5
buffering_interval = 60
}
# S3 output is automatic
}The serverless approach eliminates infrastructure management while providing the same functionality. You pay only for data processed, and scaling is automatic.
But serverless is only part of the story. Getting from “events happening” to “actionable dashboards” is still time-consuming because you have to configure and deploy multiple AWS resources:
- SQS queues with proper DLQ configuration
- Kinesis Data Firehose streams with buffering settings
- S3 buckets with partitioning and lifecycle policies
- Lambda functions for data transformation
- IAM roles and policies (often the biggest time sink)
- CloudWatch alarms and monitoring
- Resource naming and tagging conventions
Each resource needs careful IAM policy configuration, and getting the permissions right often takes longer than writing the actual logic. That’s a lot of infrastructure complexity for what should be a simple problem.
The Solution: Infrastructure as Simple Configuration
We’ve broken this into two complementary modules that make the entire pipeline reusable across projects:
1. terraform-aws-analytics-topic - Event Ingestion
Creates SNS topics with proper publisher permissions. Dead simple:
module "booking_events" {
source = "git::https://github.com/ql4b/terraform-aws-analytics-topic.git"
context = module.label.context
attributes = ["booking", "events"]
publisher_roles = [
"arn:aws:iam::${local.account_id}:role/booking-service-*"
]
}2. terraform-aws-analytics-pipeline - Complete Pipeline
Takes those events and delivers them to S3 + OpenSearch:
module "analytics" {
source = "git::https://github.com/ql4b/terraform-aws-analytics-pipeline.git"
context = module.label.context
attributes = ["analytics"]
create_queue = true
data_sources = [{
type = "sns"
arn = module.booking_events.topic_arn
}]
enable_transform = true
transform_template = "sns-transform.js"
transform = {
# Configure field mappings as needed
}
enable_opensearch = true
opensearch_config = {
domain_arn = var.opensearch_domain_arn
index_name = "analytics-events"
}
}That’s it. You now have a complete analytics pipeline.
Note: The pipeline module handles data delivery but doesn’t provision OpenSearch clusters. You’ll need to set up your OpenSearch domain separately and configure the pipeline to deliver to it.
The SQS to Firehose Bridge
SQS Queue as Reliable Buffer
We place an SQS queue at the leftmost side of the pipeline for good reason. While Firehose can handle direct writes, SQS provides:
- Guaranteed delivery with built-in retry logic
- Backpressure handling when downstream systems are overwhelmed
- Dead letter queues for failed message investigation
- Decoupling between event producers and the analytics pipeline
SQS Integration Challenge
Firehose has several native integrations:
- Kinesis Data Streams
- CloudWatch Logs and Events
- AWS IoT
- Kinesis Agent
- Direct PUT API via AWS SDK
But SQS isn’t among them. Since we want SQS for reliable buffering in our event-driven architecture, we need a bridge that uses the Firehose Direct PUT API - exactly what our Lambda bridge does.
Lambda Container Bridge
We solve this with a Lambda container bridge that polls SQS and forwards messages to Firehose. The bridge is built on our lambda-shell-runtime with AWS CLI included, so no dependency management needed.
The container image lives in public ECR but must run from your private ECR (AWS Lambda requirement). This requires a two-step deployment:
# First apply creates ECR repo and fails with:
ECR repo created: 123456789012.dkr.ecr.us-east-1.amazonaws.com/analytics-sqs-firehose-bridge
Push your image and re-apply:
aws ecr get-login-password | docker login --username AWS --password-stdin 123456789012.dkr.ecr.us-east-1.amazonaws.com
docker pull public.ecr.aws/ql4b/sqs-firehose-bridge:latest
docker tag public.ecr.aws/ql4b/sqs-firehose-bridge:latest "123456789012.dkr.ecr.us-east-1.amazonaws.com/analytics-sqs-firehose-bridge:latest"
docker push 123456789012.dkr.ecr.us-east-1.amazonaws.com/analytics-sqs-firehose-bridge:latestCopy, paste, run. Then terraform apply again and you’re done.
SNS-First Design with Future Extensibility
We built this module with SNS as the primary data source because that’s how all our systems publish events - SNS topics provide natural fan-out to multiple subscribers. SNS messages come wrapped in metadata, so our transform template automatically unwraps them and extracts MessageAttributes:
Note: We plan to enhance the module to support multiple data source types beyond SNS, but SNS covers our current production needs.
Input SNS Message:
{
"Message": "{\"jobId\":\"123\",\"status\":\"completed\"}",
"MessageAttributes": {
"service": {"Value": "booking"},
"priority": {"Value": "high"}
},
"MessageId": "abc-def-123",
"Timestamp": "2024-01-15T10:30:00Z"
}Output to Analytics:
{
"messageId": "abc-def-123",
"timestamp": "2024-01-15T10:30:00Z",
"service": "booking",
"priority": "high",
"jobId": "123",
"status": "completed"
}Dual Destination Delivery
Single Firehose stream delivers to both S3 (for long-term storage) and OpenSearch (for real-time queries). The pipeline connects to your existing OpenSearch cluster - no duplicate infrastructure, just data delivery.
Real-World Usage: Building an Analytics Hub
We’ve evolved these modules into a centralized analytics hub - a single place where we configure multiple analytics pipelines and define the SNS topics that systems publish to.
The Analytics Contract
The relationship between event-producing systems and analytics is now beautifully simple:
System responsibility: Send events to the designated SNS topic
Analytics responsibility: Grant the system’s IAM role permission to publish
That’s it. No complex integrations, no custom protocols - just standard SNS publishing.
Hub Architecture
Our analytics hub manages multiple pipelines, each as a simple module instance:
# Booking automation events
module "airswitch_events" {
source = "git::https://github.com/ql4b/terraform-aws-analytics-topic.git"
context = module.label.context
attributes = ["airswitch", "events"]
publisher_roles = [
data.terraform_remote_state.airswitch.outputs.execution_role.arn
]
}
# Flight API events
module "airline_events" {
source = "git::https://github.com/ql4b/terraform-aws-analytics-topic.git"
context = module.label.context
attributes = ["airline", "events"]
publisher_roles = [
"arn:aws:iam::${local.account_id}:role/cloudless-airline-*"
]
}
# Unified analytics pipeline
module "airlytics" {
source = "git::https://github.com/ql4b/terraform-aws-analytics-pipeline.git"
context = module.label.context
enable_transform = true
transform_template = "sns-transform.js"
transform = {
fields = [] # Include all fields
mappings = {
"@timestamp" = "created_at"
"service" = "source"
}
}
data_sources = [
{ type = "sns", arn = module.airswitch_events.topic_arn },
{ type = "sns", arn = module.airline_events.topic_arn }
]
}The Results
From event to dashboard in under 10 minutes:
- Deploy topics - Services can immediately start publishing events
- Push bridge image - One-time setup per AWS account
- Deploy pipeline - Data starts flowing to S3 and OpenSearch
- Query immediately - OpenSearch dashboards show real-time data
We’re processing thousands of automation events daily with this setup, and it scales effortlessly.
Key Takeaways
- Separate concerns: Topic creation vs. pipeline deployment
- Fail fast: Clear error messages with exact fix instructions
- Smart defaults: SNS unwrapping, dual destinations, proper partitioning
- Production ready: DLQs, CloudWatch logging, IAM least privilege
These modules emerged from real production needs - migrating a high-volume analytics system taught us what was essential versus what was just complexity. The modules are open source and battle-tested in production. Sometimes the best infrastructure is the kind you don’t have to think about.
Both modules are available on GitHub: terraform-aws-analytics-topic and terraform-aws-analytics-pipeline